
NOTE: In case you missed it, here is a link to a screencast of Kenny Bastani's webinar about using the Neo4j graph database in text classification and related Deep Learning applications. It's a fascinating introduction to some original work Kenny is doing that leverages the strengths of a property graph, in this case Neo4j, to do some Deep Learning text-mining and document classification.
This article is about what we are going to try to do with Kenny's new Graphify extension for Neo4j. And a big "Thank you!" and kudos to Kenny for kickstarting activity around this important topic within the Neo4j community.
Some Thoughts About Thinking
You would be hard-pressed to go through any formal education where you did not learn about our "two brains" – left and right hemispheres, verbal/non-verbal, creative/literal, the conscious/subconscious, long-term/short-term, self/other, etc. All these various perspectives remind us that how we think, as humans, is a complex yin-yang cognitive process. Whatever works well to help us understand ourselves and the world around us in some cases, does poorly helping us in others, and vice versa. So we've cleverly evolved the "wetware" to do both and, in one of our brains' most truly amazing feats, to provide some kind of highly effective, real-time integration of the these multiple perspectives.
One of the most intriguing distinctions to consider when attempting to model human cognitive processes (let's settle for calling it "smart software" to avoid going too far into pure ResearchSpeak) is to look at the role of subconscious and conscious processing. Some things are either so voluminous and detailed -- basic perception, for example -- that we would bore ourselves to death and slow our thinking processes to a crawl if they ran through our conscious, mostly verbal, cognitive processes. Some other aspects of our thinking -- e.g. things that produce an "A-ha!" conscious moment of discovery -- require the "hands off" focus of subconscious processing. Without such cloistered incubation opportunities, our overbearing conscious mental processes can too easily derail an otherwise breakthrough thought.
So it should not surprise us that software analogs of (something akin to) our own cognitive processing will benefit from providing a similar strategy of "complementary opposites." We should expect to find some real design opportunities for "smart software" by providing a rough approximation of this subconscious/conscious distinction as we move from an application-centric development mindset to a more appropriate agent-centric design mindset. Exploring how smart software might incorporate this "two-cyclinder thinking engine" is one of the "serious fun" R&D initiatives at FactMiners.org.
We're active in the Neo4j community because FactMiners is exploring the unique, expressive nature of graph database technology to model both how "subconscious" cognitive processing (e.g. the NLP-based stuff of Kenny's text classification webinar) can be integrated with "conscious" cognitive processing (e.g. our metamodel-subgraph GraphGists that are more akin to "mind maps"). Our belief is that such a software design strategy can lead to a synergistic result that is greater than the sum of what these simulated cognitive processes can contribute independently. To allude to popular culture, our research asks:
How can we get both the Rainman-like, obsessive-compulsive, bureaucratic, ruthlessly-detailed part of our subconscious processing to work in concert with the Sherlock Holmes-like, logical, deductive, constructive part of our "wetware"?
The Rainman Part - Kenny Bastani's Text Classification Blog/Webinar

Kenny Bastani's webinar this Thursday, "Using Neo4j for Document Classification" will provide a great live demonstration of the kind of relentless, detail-oriented, largely subconscious aspect of our human cognitive process. Kenny's recent blog post, "Using a Graph Database for Deep Learning Text Classification," is provided as a webinar supplement and gives a good introduction (with links) to the Deep Learning ideas and methods employed in his latest Open Source project, Graphify.
Graphify is a Neo4j unmanaged extension adding NLP-based (Natural Language Processing) document and text classification features to the Neo4j graph database using graph-based hierarchical pattern recognition. As Kenny describes in his blog post:
"Graphify gives you a mechanism to train natural language parsing models that extract features of a text using deep learning. When training a model to recognize the meaning of a text, you can send an article of text with a provided set of labels that describe the nature of the text. Over time the natural language parsing model in Neo4j will grow to identify those features that optimally disambiguate a text to a set of classes." (Kenny Bastani, full post)
When you read the rest of Kenny's blog post you will get a very quick and informative introduction to the Vector Space Model for Deep Learning representation and analysis of text documents. The algebraic model underlying Kenny's Graphify Neo4j extension is just the kind of Rainman-like, obsessive, detail-oriented processing that is representative of the subconscious side of our cognitive processing.
If you read the above description of Graphify closely, you will see the opportunity for synergy and integration between Graphify's "subconscious" processing and the more "conscious" processing reflected in my GraphGists exploring the "self-descriptive" Neo4j graph database.
The Sherlock Part - FactMiners' Metamodel Subgraph GraphGists

Imagine if you were able to sit down for tea with the fictional Sherlock Holmes. We hand him a paper and pen, and then ask for a description of the particulars of his latest case. Sherlock would surely resort to sketches in the form of a graph diagram or something easily mapable to a graph representation. Graph semantics are "elementary" and flexibly extensible -- properties that Sherlock would surely appreciate.
I started exploring this "conscious" cognitive process side of graph database application design in the first two parts of my GraphGist design document series, "The 'Self-Descriptive' Neo4j Graph Database: Metamodel Subgraphs in the FactMiners Social-Game Ecosystem." In the longer and more detailed second part of this GraphGist, I explored how an embedded metamodel subgraph can be used to model a "Fact Cloud" of Linked Open Data to be mined from the text and image data in the complex document structure of a magazine. In our case, we'll use FactMiners social-gameplay to "fact-mine" a digital archive of the historic Softalk magazine which chronicled the early days of the microcomputer revolution. In this regard, our "sandbox-specific" application is museum informatics. However, there is nothing domain-specific about the solution design we are pursuing.
With this more general application in mind and in looking for that opportunity where Sherlock can work hand-in-hand with Rainman, it is the first part of this GraphGist series that is the more relevant to the "whole brain" focus of this post.
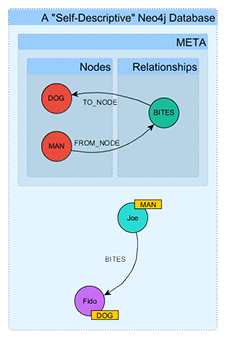
In this first part of my GraphGist, I provide a "Hello, World!" scale example of how a graph database can be 'self-descriptive' to a layer of smart software that can take advantage of this self-descriptive nature. In this gist, I had some fun exploring the old aphorism from Journalism school, "Dog bites man is nothing, but man bites dog, that's news!"
In brief, the assumption is that a 'self-descriptive' database is 'talking' to something that is listening. Under this design pattern, the listening is done by a complementary layer of "smart software" that can use this information to configure itself for all manner of data analysis, editing, and visualization, etc.
In the case of the ultra-simple "Man bites Dog" example, the layer of smart software is nothing more elaborate than some generalized metamodel-aware Cypher queries. Cypher is the built-in query language for Neo4j. In my gist example, these queries are used for "news item" discovery and validation. By simple extrapolation you can readily imagine the level of "conscious" processing that could be brought to bear to "think about" the data in a 'self-descriptive' graph database.
With this much overview of the "subconscious" and "conscious" aspects of our FactMiners' brain, we're ready to look at that opportunity for integration... that place where Rainman meets and works with Sherlock.
How Rainman and Sherlock Might Work Together

There is a strong hint at how the Deep Learning "subconscious" processing of Kenny's Graphify component might fit into the "brain model" of FactMiners. I'll underline the bits in this quote from Kenny's article to suggest the integration opportunity: "Graphify gives you a mechanism to train natural language parsing models that extract features of a text using deep learning. When training a model to recognize the meaning of a text, you can send an article of text with a provided set of labels that describe the nature of the text..."
Graphify just needs to be fed a list of those "text nature describing" labels and a pile of text to dive into and away it goes. I believe an excellent source of this "text nature knowledge" -- those labels needed to seed the training and data extraction of Kenny's "subconscious" Rainman-like text classification process -- those labels are very explicitly represented, maintained and extended in the information encoded in, and organized by, the metamodel subgraph of a 'self-descriptive' graph database.
We should be able to establish a feedback loop where Graphify's label list is supplied by Sherlock's "mental model" in the metamodel subgraph, and Graphify's results are fed back to refine or extend the metamodel. How, even whether, this will all work as envisioned we will discover over the weeks ahead.
Next up? We're looking forward to Kenny's webinar and to having some serious fun digging into Graphify.