
I am having an interesting time looking at the CIDOC-CRM – the Conceptual Reference Model for museums developed by the International Council of Museums (ICOM). In particular, as generally described in my last post, I am looking at the CIDOC-CRM with a "pure graph" lens on a metamodel developed with an object-oriented perspective.
The interesting part of my exploration has to do with bringing the "ruthless simplicity" of a graph expression to the interpretation of the CIDOC-CRM for the purpose of representing it as a Referenced Model within the metamodel partition of the graph database as part of the FactMiners' Digital Humanities-based social-game platform. I've written two complementary Neo4j-based GraphGists that explore the design pattern of an "embedded metamodel subgraph" as a means to build a fine-grained "Fact Cloud" of the referential content of the 48-issue collection of Softalk magazine covering the early history of the microcomputing revolution.
In this post, I'll take a first look at how CIDOC-CRM Property Declarations can be beneficially cast as "First Class Citizens" (AKA Nodes) in a graph model of the CIDOC-CRM. I am still in the very early stages of CIDOC-CRM exploration, so take these observations as public research notes.
The Challenges and Potential of the CIDOC-CRM
An interesting dimension of the CIDOC-CRM is that it intentionally tries to be a comprehensive conceptual model (AKA a metamodel) for not just museum artifact description, but to cover the active process of artifact curation and preservation as well as broader realms of collection management, etc. In this sense, the CIDOC-CRM goes where most cultural artifact ontologies rarely go, that is, into the realm of incorporating process along with structure-oriented model elements from which to construct our CRM-compatible model instances.
That's what a Conceptual Reference Model or metamodel is used for, at its most basic level. It's a set of model elements (parts to build a model out of) and a set of instructions that constrain how you can put these parts together. Through this model, we can share an understanding about what some domain of activity and expertise is about. That understanding is to be used, in our case, to design software systems to implement this shared conceptual (mental) understanding of what needs doing and how to do it. (I know this is not the only reason for having a comprehensive conceptual reference or metamodel, but it is the compelling reason for this exploration and discussion.)

As is often the case, industry reference models are rarely used to drive down to the granularity of "executable" in the sense of software being designed strictly to the, let's call it "semantic expressibility" of the metamodel. In other words, these conceptual reference models are most often used loosely to guide human-to-human ("mind-meld") conversation and modeling-based decision-making. But there is a lot of room for what are in effect "uncontrolled individual model transformations" (AKA we developers think about how to implement the model and then write some code that approximates our personal understanding of this shared vision). So if during implementation of metamodel-driven design there are "gotchas" or logical inconsistencies or just plain "temporal anomalies" (a big model done by committee over a long period of time), these issues are not too often show-stopping problems as we "one off" resolve these issues by "coding band-aids" as we go along.
But one of the goals that the CIDOC-CRM SIG group members aspire to encourage and support is research-based inference and deductibility – text- and image-based computational analytics – for CIDOC-CRM compatible datastores and associated #LODLAM web services. In other words, "close enough for horseshoes or hand grenades" may be good enough for many cases of using a conceptual reference model for indirect reference, but this is not good enough if we are going for fact- or inference-discovery and validation via metamodel-constrained computational analytics.
So let's look at the most obvious case in point; Property Declarations as "faux" relationships between CRM Classes.
CIDOC-CRM Property Declarations as "Shortcut" Classes
A typical CIDOC-CRM graphical diagram of key parts of the model shows the graph-based shared understanding of how we're "thinking about" this museum conceptual model. The "object"-like things are drawn as nodes and have "E-prefix" names that reflect their "IS_A" (object-oriented inheritance) descent from the "E1 CRM Entity" root of the CIDOC-CRM Class Hierarchy. The relationships (or edges in a pure graph sense) between Classes (AKA our graph-based Nodes) are defined as CIDOC-CRM Properties. CIDOC-CRM Properties have a "Pnum-prefix" name and have the additional facet of "bidirectional/reflexive naming" -- e.g. P67 "refers to/is referred to by" providing the appropriate human-readable interpretation of the named relationship based on which "end" of the relationship you want to anchor your mental understanding of the described relationship.
To understand how this current view on the CIDOC-CRM is problematic to a "pure graph" expression, let's look at a particularly interesting cluster of CIDOC-CRM model elements (both Classes and Properties) that describe the "Image Information, Objects and Carriers". I've highlighted the aspects of this diagram of the CIDOC-CRM definition that cannot be expressed in a basic graph representation.
This subset of CIDOC-CRM model elements is especially interesting as it gets to the core of our FactMiners' design interest – and that is, "piercing the veil" to move our Fact Cloud coverage from artifact description to deep analysis by modeling the artifact's representational meaning. In our case, we require a metamodel sufficient to cover the complex structure of a commerical magazine while providing the granularity to model – based on CIDOC-CRM-compatible form – the 48 monthly snapshots of the cacophonous "Open World" of activity at the dawn of the Microcomputer Revolution as depicted in the incredible content of this historic magazine archive.
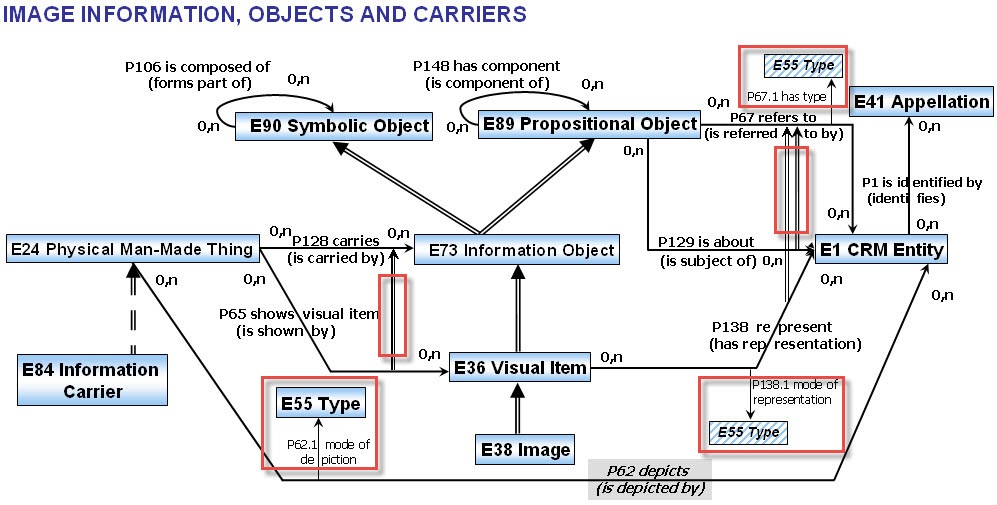
The eagle-eyed "graphistas" among you will notice a show-stopping gotcha. Those double-line arrows from relationship-to-relationship violate the essential "ruthless simplicity" of a pure graph model. A graph is just nodes and relationships, with relationships being the edge/line links BETWEEN nodes. There are no relationships between relationships in basic graph theory.
Fortunately, this is not a show-stopping problem. It just suggests that the view we're given is more a "mental shortcut" for a graph expression that models the relationship as a distinct type of Class. In this way, a "node-ified" CIDOC-CRM Property can be modeled with respect to its "IS_A" subproperty/superproperty relationships as well as support the "Pnum.1" idiom where property specializations can be expressed through "mode of X" relationships to "E55 Type" entities, etc.
In other words, here is how we can look at a portion of the "Image Information, Objects and Carriers" model with "node-ified" CIDOC-CRM Property Declarations:
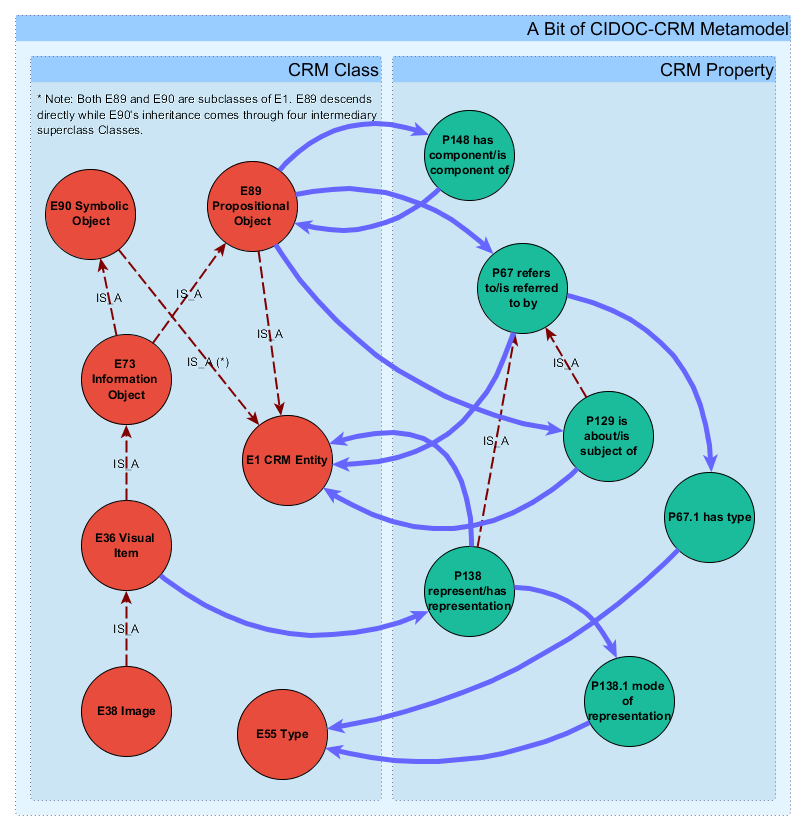
In this diagram, the "subset-membership containment areas" are a visualization of, in Neo4j graph database-terms, a label-based conceptual type. That is, our metamodel of the CIDOC-CRM contains Nodes that are of type "CRM Class" and a collection of Nodes of type "CRM Property." These two labeled subsets are emphasized in the graphic by node color in addition to their containment in subset-membership labeled boxes.
Now that we have a "node-ified" Property "P138 represent/has representation" represented in our graph as a node, we can create its "subproperty of" relationship to "P76 refers to/is referred to by." This "subproperty of" relationship, by the way, can be thought of as a specialization of the "IS_A" relationship underlying the object-oriented CIDOC-CRM Class subclass and superclass inheritance relationships. Note, too, that we can easily create the "Pnum.1" relationships that provide specialization of a CRM Property.
[Note: The above diagram is decidedly high-level. A full rendering of a "pure graph" expression of the CIDOC-CRM would show labeled domain/range relationships, cardinality, etc. These fine-grained aspects of the model are left off here to keep the explanatory diagram cleaner.]
Okay, but so what? Why "node-ify" CRM Properties?
At some level we could think, "Okay, so what?" Aren't we just nit-picking over the details of the metamodel representation for communication and system design discussions. For many, yes, that's true. But the FactMiners LAM-based social-game platform is being designed with an underlying cognitive computing perspective. We need our metamodel expression of the CIDOC-CRM to be machine-executable.
This aspiration for deep computational analysis of cultural artifacts is also one held by members of the CIDOC-CRM Special Interest Group. Dominic Oldman – a CIDOC-CRM SIG member, Principle Investigator of www.ResearchSpace.org, and IT exec of The British Museum – writes in the latest version of "The CIDOC Conceptual Reference Model (CIDOC CRM): PRIMER" (my emphasis added):
"The most important kinds of computer-based reasoning the CRM can support are generalisations of relationships and deductions from highly indirect relations such as what parts have in common with their wholes, what wholes inherit from their parts and what is transferred across meetings and processes of derivation. These are not meant to replace scholarly conclusions but to comprehensively detect facts relevant to answer research questions. Besides others this ensures that highly specialized knowledge stays accessible to generic questions regardless the specificity of representation."
My belief is that a fully-realized graph expression of the CIDOC-CRM will not just support the kind of "fact-checking" and discovery that Dominic asserts in the quote above, but will move CIDOC-CRM-based computational analytics into the realm of significant first-class, fine-grained, traceable, interpretive scholarship that is only just beginning to be imagined based on the rapid advances in Deep Learning, Natural Language Processing, Image Scene Recognition, and other aspects of the explosion of advances in what is being loosely corralled by the term "Cognitive Computing."
While my example is ruthlessly simple for the purpose of introductory explanation and is not CIDOC-CRM-specific, the first part of my two-part GraphGist demonstrates how generalized query-based fact discovery and validation can be performed on a "self-descriptive" Neo4j-based graph database. And closely related to this GraphGist is the research agenda described in my "Rainman Meet Sherlock" post.
I welcome your thoughts and/or questions.